count(*)会统计为null的字段,count(1)和count(列名)不会统计该列为null的字段
查询速度count(主键)>count(1)>count(*)
distinct count(*)返回不重复且不含null的值
count(*)会统计为null的字段,count(1)和count(列名)不会统计该列为null的字段
查询速度count(主键)>count(1)>count(*)
distinct count(*)返回不重复且不含null的值
利用哈希表插入和查找都是O(1)的时间复杂度,把数组的数先插入哈希表,去除了重复元素。O(n)
再对HashSet里面的数,如果这个数减一不在这个表里面,那么把它当成开始元素,记录有多少个连续。O(n)
O(n)+O(n)=O(n)
1 | /** |
Mysql的InnoDB引擎索引采用B+树的类型,所有的主键索引可以直接通过B+树找到对应,非主键索引需要通过一次B+树找到主键,然后再通过主键索引找到对应。

1)排序方式:所有节点关键字是按递增次序排列,并遵循左小右大原则;
(2)子节点数:非叶节点的子节点数>1,且<=M ,且M>=2,空树除外(注:M阶代表一个树节点最多有多少个查找路径,M=M路,当M=2则是2叉树,M=3则是3叉);
(3)关键字数:枝节点的关键字数量大于等于ceil(m/2)-1个且小于等于M-1个(注:ceil()是个朝正无穷方向取整的函数 如ceil(1.1)结果为2);
(4)所有叶子节点均在同一层、叶子节点除了包含了关键字和关键字记录的指针外也有指向其子节点的指针只不过其指针地址都为null对应下图最后一层节点的空格子;
最后我们用一个图和一个实际的例子来理解B树(这里为了理解方便我就直接用实际字母的大小来排列C>B>A)
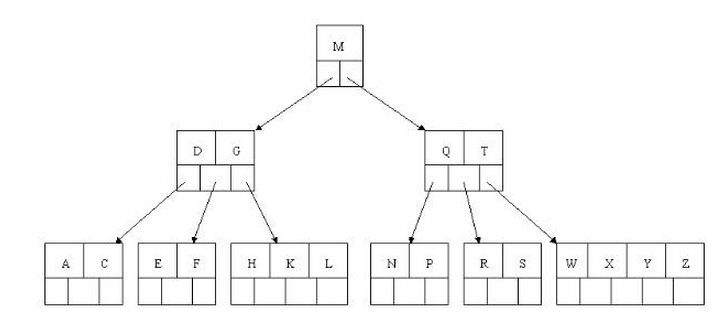
如上图我要从上图中找到E字母,查找流程如下
(1)获取根节点的关键字进行比较,当前根节点关键字为M,E<M(26个字母顺序),所以往找到指向左边的子节点(二分法规则,左小右大,左边放小于当前节点值的子节点、右边放大于当前节点值的子节点);
(2)拿到关键字D和G,D<E<G 所以直接找到D和G中间的节点;
(3)拿到E和F,因为E=E 所以直接返回关键字和指针信息(如果树结构里面没有包含所要查找的节点则返回null);
相对于B树,B+树只有在叶子节点才是data,非叶子节点只具有索引作用。
每个叶子节点都有一个指针,指向下一个数据,形成一个有序链表。

1、B+树的层级更少:相较于B树B+每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快;
2、B+树查询速度更稳定:B+所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定;
3、B+树天然具备排序功能:B+树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高。
4、B+树全节点遍历更快:B+树遍历整棵树只需要遍历所有的叶子节点即可,,而不需要像B树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
B树相对于B+树的优点是,如果经常访问的数据离根节点很近,而B树的非叶子节点本身存有关键字其数据的地址,所以这种数据检索的时候会要比B+树快。
1 | /** |
利用栈,对格子比栈顶小的就入栈,比栈顶大的就出栈,然后比较当前的元素和栈顶的元素的距离,以及高度差,继续比较,直到当前位置小于栈顶元素,入栈。
1 | /** |
双向链表,由于水的盛水容量是由短板决定的,所以哪边是短板就移动,这样才有可能使得盛水容量变大。